01-hello world
Write a program that uses MPI and has each MPI process print Hello world from process i of n.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#include <stdio.h>
#include "mpi.h"
int main(int argc, char **argv)
{
int rank, size;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
printf("Hello world from process %d of %d\n", rank, size);
MPI_Finalize();
return 0;
}
|
这里重点解释:MPI_Comm_size用于获取该通信域内的总进程数,如果通信域为MP_COMM_WORLD,即获取总进程数;MPI_Comm_rank用于获得当前进程的进程标识,如进程0在执行该函数时,可以获得返回值0。
1
2
3
4
5
6
7
8
|
Ther% mpicc 01-hello.c -o 01-hello
Ther% ./01-hello
Hello world from process 0 of 1
Ther% mpirun -np 4 01-hello
Hello world from process 1 of 4
Hello world from process 3 of 4
Hello world from process 2 of 4
Hello world from process 0 of 4
|
注意程序有两种启动方式:若直接启动,则只开启一个进程;若使用mpirun指令,则可以同时启动多个进程。
02-sharing data
Write a program that reads an integer value from the terminal and distributes the value to all of the MPI processes. Each process should print out its rank and the value it received. Values should be read until a negative integer is given as input.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#include <stdio.h>
#include "mpi.h"
int main(int argc, char **argv)
{
int rank, value;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
do
{
if (rank == 0)
scanf("%d", &value);
MPI_Bcast(&value, 1, MPI_INT, 0, MPI_COMM_WORLD);
printf("Process %d got %d\n", rank, value);
} while (value >= 0);
MPI_Finalize();
return 0;
}
|
这一任务本质上是将主进程上的值广播到其他进程,用到的MPI_Bcast函数定义如下:
1
2
3
4
5
6
7
8
|
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)
/*
buffer: starting address of buffer (choice)
count: number of entries in buffer (integer)
datatype: data type of buffer (handle)
root: rank of broadcast root (integer)
comm: communicator (handle)
*/
|
03-sending in a ring
Write a program that takes data from process zero and sends it to all of the other processes by sending it in a ring. That is, process i should receive the data and send it to process i+1, until the last process is reached.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
#include <stdio.h>
#include "mpi.h"
int main(int argc, char **argv)
{
int rank, value, size;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
do
{
if (rank == 0)
{
scanf("%d", &value);
MPI_Send(&value, 1, MPI_INT, rank + 1, 0, MPI_COMM_WORLD);
}
else
{
MPI_Recv(&value, 1, MPI_INT, rank - 1, 0, MPI_COMM_WORLD, &status);
if (rank < size - 1)
MPI_Send(&value, 1, MPI_INT, rank + 1, 0, MPI_COMM_WORLD);
}
printf("Process %d got %d\n", rank, value);
} while (value >= 0);
MPI_Finalize();
return 0;
}
|
MPI_Send和MPI_Recv的用法详见MPI_Send和MPI_Recv。这里注意以下几个参数:
- tag:信息标志,同为整型变量,发送和接收需要tag一致,这将可以区分同一目的地的不同消息。
- status:在Recv中用于返回状态信息,可以通过
status.MPI_SOURCE,status.MPI_TAG和status.MPI_ERROR的方式调用这三个信息。这三个信息分别返回的值是所收到数据发送源的进程号,该消息的tag值和接收操作的错误代码。
04-estimate $\pi$
This exercise presents a simple program to determine the value of pi. The algorithm suggested here is chosen for its simplicity. The method evaluates the integral of 4/(1+x*x) between 0 and 1. The method is simple: the integral is approximated by a sum of n intervals; the approximation to the integral in each interval is (1/n)*4/(1+x*x). The master process (rank 0) asks the user for the number of intervals; the master should then broadcast this number to all of the other processes. Each process then adds up every n’th interval (x = rank/n, rank/n+size/n,…). Finally, the sums computed by each process are added together using a reduction.
$$
\pi = \int_0^1 \frac{4}{1+x^2}dx
$$
翻译一下要求:我们将积分可以分成N小段求和,每一段的求和是独立的,可以通过并行计算完成。主进程得到N值,而后分发给N个子进程进行运算,最后将求和结果发回给父进程。
$$
\pi = \frac{1}{N} \times \sum_{i=1}^N(\frac{4}{1+x^2})|_{x=\frac{2i-1}{2N}}
$$
接下来是核心的计算实现部分:以4个进程为例,我们想把100次循环计算分给4个进程。最佳的实现方法是使用0进程计算1,5,9,1进程计算2,6,10…,这样会使各个进程的逻辑实现是相同的。
最后各进程的求和操作采用了MPI_Reduce,这一函数用于将所有进程的值“合并”为同一个值,并送到主进程。这一操作也叫做”规约操作“。
规约是一类并行算法,对传入的N个数据,使用一个二元的符合结合律的操作符⊕,生成1个结果。这类操作包括取最小、取最大、求和、平方和、逻辑与/或、向量点积。规约也是其他高级算法中重要的基础算法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
#include <math.h>
#include <stdio.h>
#include "mpi.h"
int main(int argc, char **argv)
{
int done = 0, n, myid, numprocs, i;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
while (!done)
{
if (myid == 0) // choose the main process
{
printf("Enter the number of intervals: (0 quits) ");
scanf("%d", &n);
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD); // broadcast the number of intervals to all processes
if (n == 0)
break;
h = 1.0 / (double)n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs) // the gap is number of process
{
x = h * ((double)i - 0.5);
sum += 4.0 / (1.0 + x * x);
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (myid == 0)
printf("pi is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT));
}
MPI_Finalize();
return 0;
}
|
05-fairness in message passing
Write a program to test how fair the message passing implementation is. To do this, have all processes except process 0 send 100 messages to process 0. Have process 0 print out the messages as it receives them, using MPI_ANY_SOURCE and MPI_ANY_TAG in MPI_Recv.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
#include "mpi.h"
#include <stdio.h>
int main(int argc, char **argv)
{
int rank, size, i, buf[1];
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (rank == 0)
{
for (i = 0; i < 100 * (size - 1); i++)
{
MPI_Recv(buf, 1, MPI_INT, MPI_ANY_SOURCE,
MPI_ANY_TAG, MPI_COMM_WORLD, &status);
printf("Msg from %d with tag %d\n",
status.MPI_SOURCE, status.MPI_TAG);
}
}
else
{
for (i = 0; i < 100; i++)
{
MPI_Send(buf, 1, MPI_INT, 0, i, MPI_COMM_WORLD);
}
}
MPI_Finalize();
return 0;
}
|
这里主要实现了信息的过滤和筛选。MPI_ANY_SOURCE和MPI_ANY_TAG对信息的进程来源和TAG不作约束,否则不符合要求的信息就会被过滤。
06-parallel data structure
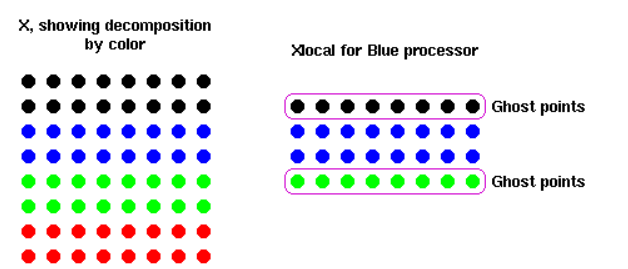
原题就不贴了,翻译一下:有一个数据结构double x[maxn][maxn],我们想要将其分配给若干个进程double xlocal[maxn][maxn/size]。然而在更新数据x[i][j]时,需要相邻的4个值:x[i][j+1] x[i][j-1] x[i+1][j] x[i-1][j]。这些值不一定在同一个进程上,同步比较麻烦,我们需要设计算法进行同步。我们将这些不在同一个进程上的点定义为“ghost point”。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
#include <stdio.h>
#include "mpi.h"
/* This example handles a 12 x 12 mesh, on 4 processors only. */
#define maxn 12
int main(int argc, char **argv)
{
int rank, value, size, errcnt, toterr, i, j;
MPI_Status status;
double x[12][12];
double xlocal[(12 / 4) + 2][12]; // 4 processors, with 2 ghostpoints
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (size != 4)
MPI_Abort(MPI_COMM_WORLD, 1); // Abort if not 4 processors
/* xlocal[][0] is lower ghostpoints, xlocal[][maxn+2] is upper */
/* Fill the data as specified */
for (i = 1; i <= maxn / size; i++) // initialize the local array
for (j = 0; j < maxn; j++)
xlocal[i][j] = rank;
for (j = 0; j < maxn; j++) // initialize the ghostpoints
{
xlocal[0][j] = -1;
xlocal[maxn / size + 1][j] = -1;
}
/* Send up unless I'm at the top, then receive from below */
/* Note the use of xlocal[i] for &xlocal[i][0] */
if (rank < size - 1)
MPI_Send(xlocal[maxn / size], maxn, MPI_DOUBLE, rank + 1, 0,
MPI_COMM_WORLD);
if (rank > 0)
MPI_Recv(xlocal[0], maxn, MPI_DOUBLE, rank - 1, 0, MPI_COMM_WORLD,
&status);
/* Send down unless I'm at the bottom */
if (rank > 0)
MPI_Send(xlocal[1], maxn, MPI_DOUBLE, rank - 1, 1, MPI_COMM_WORLD);
if (rank < size - 1)
MPI_Recv(xlocal[maxn / size + 1], maxn, MPI_DOUBLE, rank + 1, 1,
MPI_COMM_WORLD, &status);
/* Check that we have the correct results */
errcnt = 0;
for (i = 1; i <= maxn / size; i++)
for (j = 0; j < maxn; j++)
if (xlocal[i][j] != rank)
errcnt++;
for (j = 0; j < maxn; j++)
{
if (xlocal[0][j] != rank - 1)
errcnt++;
if (rank < size - 1 && xlocal[maxn / size + 1][j] != rank + 1)
errcnt++;
}
MPI_Reduce(&errcnt, &toterr, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0)
{
if (toterr)
printf("! found %d errors\n", toterr);
else
printf("No errors\n");
}
MPI_Finalize();
return 0;
}
|
代码的整体逻辑如下:首先初始化好每一个process上的local value和ghost value,之后根据条件将每一个process的第一行/最后一行分别发送给上一个/下一个process,ghost value得到了更新(这里有几个细节需要注意:首先是发送个数和发送TAG,其次Send和Recv的先后)。
不过这样有一个问题:ghost value的存在增大了进程的本地开销,能否有更省空间的方法?
07-jacobi iteration
本节实现的jacobi iteration的计算公式如下:
$$
a[i][j] = 0.25(a[i - 1][j] + a[i + 1][j] + a[i][j - 1] + a[i][j + 1])
$$
首先看默认解法。进程间的通信思路和上一小节类似,此处不再赘述,贴出代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
#include <stdio.h>
#include <math.h>
#include "mpi.h"
/* This example handles a 12 x 12 mesh, on 4 processors only. */
#define maxn 12
int main(int argc, char **argv)
{
int rank, value, size, errcnt, toterr, i, j, itcnt;
int i_first, i_last;
MPI_Status status;
double diffnorm, gdiffnorm;
double xlocal[(12 / 4) + 2][12];
double xnew[(12 / 3) + 2][12];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (size != 4)
MPI_Abort(MPI_COMM_WORLD, 1);
/* xlocal[][0] is lower ghostpoints, xlocal[][maxn+2] is upper */
/* Note that top and bottom processes have one less row of interior
points */
i_first = 1;
i_last = maxn / size;
if (rank == 0)
i_first++;
if (rank == size - 1)
i_last--;
/* Fill the data as specified */
for (i = 1; i <= maxn / size; i++)
for (j = 0; j < maxn; j++)
xlocal[i][j] = rank;
for (j = 0; j < maxn; j++)
{
xlocal[i_first - 1][j] = -1;
xlocal[i_last + 1][j] = -1;
}
itcnt = 0;
do
{
/* Send up unless I'm at the top, then receive from below */
/* Note the use of xlocal[i] for &xlocal[i][0] */
if (rank < size - 1)
MPI_Send(xlocal[maxn / size], maxn, MPI_DOUBLE, rank + 1, 0,
MPI_COMM_WORLD);
if (rank > 0)
MPI_Recv(xlocal[0], maxn, MPI_DOUBLE, rank - 1, 0,
MPI_COMM_WORLD, &status);
/* Send down unless I'm at the bottom */
if (rank > 0)
MPI_Send(xlocal[1], maxn, MPI_DOUBLE, rank - 1, 1,
MPI_COMM_WORLD);
if (rank < size - 1)
MPI_Recv(xlocal[maxn / size + 1], maxn, MPI_DOUBLE, rank + 1, 1,
MPI_COMM_WORLD, &status);
/* Compute new values (but not on boundary) */
itcnt++;
diffnorm = 0.0;
for (i = i_first; i <= i_last; i++)
for (j = 1; j < maxn - 1; j++)
{
xnew[i][j] = (xlocal[i][j + 1] + xlocal[i][j - 1] +
xlocal[i + 1][j] + xlocal[i - 1][j]) /
4.0;
diffnorm += (xnew[i][j] - xlocal[i][j]) *
(xnew[i][j] - xlocal[i][j]);
}
/* Only transfer the interior points */
for (i = i_first; i <= i_last; i++)
for (j = 1; j < maxn - 1; j++)
xlocal[i][j] = xnew[i][j];
MPI_Allreduce(&diffnorm, &gdiffnorm, 1, MPI_DOUBLE, MPI_SUM,
MPI_COMM_WORLD);
gdiffnorm = sqrt(gdiffnorm);
if (rank == 0)
printf("At iteration %d, diff is %e\n", itcnt,
gdiffnorm);
} while (gdiffnorm > 1.0e-2 && itcnt < 100);
MPI_Finalize();
return 0;
}
|
注意在编译时需要链接libm.so:
1
|
mpicc 07-jacobi-iteration.c -o 07-jacobi-iteration -lm
|
这里出现了一个新函数MPI_Allreduce。许多并行程序中,需要在所有进程而不是仅仅在根进程中访问归约的结果,与MPI_reduce不同的是,MPI_Allreduce 将归约所有值并将结果分配给所有进程。
当然,以上代码还有改进的空间:在代码规模大且程序结构复杂的情况下,匹配SEND和RECV需要额外花费较多精力。我们注意到在此例中SEND和RECV是成对出现的,我们可以将其绑定(使用MPI_Sendrecv);同时,最上方和最下方由于格式不统一需要进行单独编写,我们可以引入虚拟进程MPI_PROC_NULL来对代码进行规范化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
- if (rank < size - 1)
- MPI_Send(xlocal[maxn / size], maxn, MPI_DOUBLE, rank + 1, 0,
- MPI_COMM_WORLD);
- if (rank > 0)
- MPI_Recv(xlocal[0], maxn, MPI_DOUBLE, rank - 1, 0,
- MPI_COMM_WORLD, &status);
- if (rank > 0)
- MPI_Send(xlocal[1], maxn, MPI_DOUBLE, rank - 1, 1,
- MPI_COMM_WORLD);
- if (rank < size - 1)
- MPI_Recv(xlocal[maxn / size + 1], maxn, MPI_DOUBLE, rank + 1, 1,
- MPI_COMM_WORLD, &status);
+ MPI_Sendrecv(xlocal[maxn / size], maxn, MPI_DOUBLE, rank < size - 1 ? rank + 1 : MPI_PROC_NULL, 0, xlocal[0], maxn, MPI_DOUBLE, rank > 0 ? rank - 1 : MPI_PROC_NULL, 0, MPI_COMM_WORLD, &status);
+ MPI_Sendrecv(xlocal[1], maxn, MPI_DOUBLE, rank > 0 ? rank - 1 : MPI_PROC_NULL, 1, xlocal[maxn / size + 1], maxn, MPI_DOUBLE, rank < size - 1 ? rank + 1 : MPI_PROC_NULL, 1, MPI_COMM_WORLD, &status);
|
08-collecting data
这是上一节的延续。我们需要将迭代结果在主进程中显示。此处用到了MPI_Gather函数,用于将所有进程的数据进行聚合(没有规约等操作)。
1
2
3
4
5
6
|
/* Collect the data into x and print it */
/* This code (and the declaration of x above) are the only changes to the
Jacobi code */
MPI_Gather(xlocal[1], maxn * (maxn / size), MPI_DOUBLE,
x, maxn * (maxn / size), MPI_DOUBLE,
0, MPI_COMM_WORLD);
|
我们看一下Gather的操作:参数定义了每一个send buffer的起始地址和长度,以及recv buffer的起始地址和每一次接收的长度。接收到的数据按照进程号排列。
Reference
Tutorial material on MPI available on the Web