流水线计算公式
$n$为指令数,$k$为流水线级数,级间延时$\Delta t$。
实际吞吐率(单位时间内流水线处理的指令数): $$ TP=\frac{n}{(k+n-1)\Delta t} $$ 最大吞吐率: $$ TP_{max} = \frac{1}{\Delta t} $$ 实际加速比: $$ S = \frac{kn}{k+n-1} $$ 最大加速比: $$ S_{max}=k $$
流水线中控制信号的流动
控制信号在IF之后的ID/RF阶段产生。
- ID/RF:Extop
- EX:ALUSrc、ALUOp、RegDst??
- MEM:MemWrite、Branch
- WB:MemToReg、RegWrite
流水线中的冒险
首先列出未冒险时流水线CPU在各步中进行的操作:
| R | lw or sw | beq | J | |
|---|---|---|---|---|
| IF | PC<=PC+4; IR <=MemInst[PC] |
* | * | * |
| ID | opcode<=IR[31:26]; A<=Reg[IR[25:21]]; B<=Reg[IR[20:16]]; ALUOut<=PC+(signext(IR[15:0]<<2)) |
* | * | PC <= {PC[31:28],IR[25:0],2’b00} |
| EX | ALUOut <= A op B |
ALUOut<=A+sign-ext(IR[15:0]) |
if (A=B)PC<=ALUOut |
|
| MEM | Reg[IR[15:11]]<=ALUOut |
Lw:MDR<=MemData[ALUOut];Sw:MemData[ALUout] <=B |
||
| WB | Reg[IR[20:16]] <=MDR |
结构冒险
problem
流水线处理器中直接取消了InstMemory和DataMemory混用的做法,因此不必担心存储器访问的冲突。
- ALU使用冲突。考虑下列指令:
|
|
当add指令执行完EX时,beq指令执行完ID,ALU产生冲突的结果。
- 寄存器堆写入冲突。考虑下列指令:
|
|
当add指令执行完MEM时,lw指令执行完WB,寄存器写入数据产生冲突的结果。
solution
-
ALU使用冲突:
beq指令原先需要进行两次计算操作:1)在ID阶段计算分支地址 2)在EX阶段作差比较,更新PC。
现在需要将计算分支地址移动到EX阶段,把ALUOut计算分解为ALU和PCAdd(一个周期进行两次计算),在MEM阶段更新PC。
-
寄存器堆写入冲突:
将R型的Write back移动到WB阶段。
更新后的操作如下:
| R | lw or sw | beq | J | |
|---|---|---|---|---|
| IF | PC<=PC+4; IR <=MemInst[PC]; |
* | * | * |
| ID | opcode<=IR[31:26]; A<=Reg[IR[25:21]]; B<=Reg[IR[20:16]]; |
* | * | PC <= {PC[31:28],IR[25:0],2’b00} |
| EX | ALUOut <= A op B |
ALUOut<=A+sign-ext(IR[15:0]) |
ALUOut<=A-B; PCAdd<=PC+(signext(IR[15:0]<<2)) |
|
| MEM | Lw:MDR<=MemData[ALUOut]; Sw:MemData[ALUout] <=B |
if(Zero) PC<=PCAdd |
||
| WB | Reg[IR[15:11]]<=ALUOut |
Reg[IR[20:16]] <=MDR |
数据冒险
无法得到所需的数据而导致不能执行后续指令。数据冒险面对的是操作数是否已经更新的问题。
| R | lw or sw | beq | J | |
|---|---|---|---|---|
| IF | PC<=PC+4; IR <=MemInst[PC]; |
* | * | * |
| ID | opcode<=IR[31:26]; A<=Reg[IR[25:21]]; B<=Reg[IR[20:16]]; |
* | * | PC <= {PC[31:28],IR[25:0],2’b00} |
| EX | ALUOut <= A op B |
ALUOut<=A+sign-ext(IR[15:0]) |
ALUOut<=A-B; PCAdd<=PC+(signext(IR[15:0]<<2)) |
|
| MEM | Lw:MDR<=MemData[ALUOut]; Sw:MemData[ALUout] <=B |
if(Zero) PC<=PCAdd |
||
| WB | Reg[IR[15:11]]<= ALUOut |
Reg[IR[20:16]] <= MDR |
Read after write data hazards(RAW)
硬件优化
考虑以下指令:
|
|
before:
add $r1,$r2,$r3 |
IF | ID | EX | MEM | WB | ||
nop |
|||||||
nop |
|||||||
add $r2,$r1,$r3 |
IF | ID | EX | MEM |
注意到第一条指令在WB阶段将结果写回寄存器(注意已经不是MEM阶段了!),而第二条指令在ID阶段读取寄存器。可以不修改数据通路,但是需要保证寄存器先写后读(否则需要阻塞3个周期)。
实现方法:
- 流水线上的寄存器在上升沿时写入,在时钟的下降沿写入寄存器堆。
- 比较写入地址和读取地址,当两者相同且要写入寄存器堆时,读取端的数据直接选择为写入端的数据而不从寄存器堆中读取。
Forward(转发)
考虑以下指令:
|
|
after:
add $r1,$r2,$r3 |
IF | ID | EX | MEM | WB | ||
sub $r4,$r1,$r5 |
IF | ID | EX | MEM | WB | ||
and $r6,$r1,$r7 |
IF | ID | EX | MEM | WB |
指令1在WB阶段写入r1寄存器,但指令2、3在ID阶段就要用到r1。不过实际上在指令的EX阶段该数值就已经计算完毕,需要在指令2、3的EX阶段用到。
对于指令2,EX的操作数来源于EX/MEM.ALUOut;对于指令3,EX的操作数来源于MEM/WB.ALUOut;
Load-use data hazard(lw-calculate type)
Forward
考虑以下指令:
|
|
before:
lw $r1,100($r2) |
IF | ID | EX | MEM | WB | ||
nop |
|||||||
nop |
|||||||
sub $r4,$r1,$r5 |
IF | ID | EX | MEM | |||
and $r6,$r1,$r7 |
IF | ID | EX |
after:
lw $r1,100($r2) |
IF | ID | EX | MEM | WB | ||
sub $r4,$r1,$r5 |
IF | ID | EX | MEM | WB | ||
and $r6,$r1,$r7 |
IF | ID | EX | MEM |
lw后r1的新值在MEM阶段后产生,随后被转发至MDR(注意此处的MDR与多周期中的MDR不同,此处的MDR应该是MEM/WB的一部分)中,在下个周期供sub的EX阶段使用。
上述方法必须使用一次stall,可以重排指令,在lw之后运行一条不依赖r1寄存器的指令。
更新后的操作如下:
| R | lw or sw | beq | J | |
|---|---|---|---|---|
| IF | PC<=PC+4; IR <=MemInst[PC]; | * | * | * |
| ID | opcode<=IR[31:26]; A<=Reg[IR[25:21]]; B<=Reg[IR[20:16]]; | * | * | PC <= {PC[31:28],IR[25:0],2’b00} |
| EX | ALUOut <= A op B; (Register,EX/MEM.ALUOut,MEM/WB.ALUOut,MDR) | ALUOut<=A+sign-ext(IR[15:0]); (Register,EX/MEM.ALUOut,MEM/WB.ALUOut,MDR) | ALUOut<=A-B; PCAdd<=PC+(signext(IR[15:0]«2)) | |
| MEM | Lw:MDR<=MemData[ALUOut]; Sw:MemData[ALUout] <=B | if(Zero) PC<=PCAdd | ||
| WB | Reg[IR[15:11]]<=ALUOut | Reg[IR[20:16]] <=MDR |
Load-use data hazard(lw-sw type)
考虑以下指令:
|
|
before
lw $a0,10($a1) |
IF | ID | EX | MEM | WB | ||
nop |
|||||||
sw $a0,10($a2) |
IF | ID | EX | MEM | WB |
after
lw $a0,10($a1) |
IF | ID | EX | MEM | WB | ||
sw $a0,10($a2) |
IF | ID | EX | MEM | WB |
lw在MEM阶段结束后更新a0的值,此时可以直接转发给sw,以供在下一时钟周期存入存储器。
注意与以下情景做区分:
1 2lw $t4, 0($t0) sw $t0, 0($t4)这就不是lw-sw type了,解决方案见lw-calculate type。
控制冒险
取到的指令可能不是所需要的,导致指令不能在预定的时钟周期内执行。控制冒险面对的是下一条指令的PC是多少的问题。
| R | lw or sw | beq | J | |
|---|---|---|---|---|
| IF | PC<=PC+4; IR <=MemInst[PC]; | * | * | * |
| ID | opcode<=IR[31:26]; A<=Reg[IR[25:21]]; B<=Reg[IR[20:16]]; | * | * | PC <= {PC[31:28],IR[25:0],2’b00} |
| EX | ALUOut <= A op B; (Register,EX/MEM.ALUOut,MEM/WB.ALUOut,MDR) | ALUOut<=A+sign-ext(IR[15:0]); (Register,EX/MEM.ALUOut,MEM/WB.ALUOut,MDR) | ALUOut<=A-B; PCAdd<=PC+(signext(IR[15:0]«2)) | |
| MEM | Lw:MDR<=MemData[ALUOut]; Sw:MemData[ALUout] <=B(B,MEM/WB.MemReadData) | if(Zero) PC<=PCAdd | ||
| WB | Reg[IR[15:11]]<=ALUOut | Reg[IR[20:16]] <=MDR |
beq hazard
考虑如下指令:
|
|
before:
beq $t1,$t2,0x10 |
IF | ID | EX | MEM | WB | ||
nop |
|||||||
nop |
|||||||
nop |
|||||||
add $a3,$a2,$a1 |
IF | ID | EX |
beq在MEM阶段才执行跳转,在WB阶段将目标地址写入PC,写入PC后下一条指令在IF阶段取用PC,默认情况下需要stall 3个周期,否则下一条指令执行可能会发生错误。
但实际上判断是否需要跳转的所有条件在EX阶段执行后就可以全部掌握,可以将ALUOut转发的结果转发至IF,这样只需要stall 2个周期。
after(v1):
beq $t1,$t2,0x10 |
IF | ID | EX | MEM | WB | ||
nop |
|||||||
nop |
|||||||
add $a3,$a2,$a1 |
IF | ID | EX | MEM |
实际上,也可以将分支判断移动到ID阶段:
| R | lw or sw | beq | J | |
|---|---|---|---|---|
| IF | PC<=PC+4; IR <=MemInst[PC]; | * | * | * |
| ID | opcode<=IR[31:26]; A<=Reg[IR[25:21]]; B<=Reg[IR[20:16]]; | * | if(A==B) PC<=PC+(signext(IR[15:0]«2)) | PC <= {PC[31:28],IR[25:0],2’b00} |
| EX | ALUOut <= A op B; (Register,EX/MEM.ALUOut,MEM/WB.ALUOut,MDR) | ALUOut<=A+sign-ext(IR[15:0]); (Register,EX/MEM.ALUOut,MEM/WB.ALUOut,MDR) | ||
| MEM | Lw:MDR<=MemData[ALUOut]; Sw:MemData[ALUout] <=B(B,MEM/WB.MemReadData) | |||
| WB | Reg[IR[15:11]] <=ALUOut | Reg[IR[20:16]] <=MDR |
但是可能会带来一些新的问题:
-
在EX阶段我们使用ALU比较两个操作数是否相等,使用PCAdder计算分支地址,所以现在需要在ID阶段额外引入比较器和PC计算器。注意到数据可能来自旁路。
-
在ID阶段判断beq,等价于将beq的EX阶段提前进行,这样就会产生3种情况:
- beq前1条指令为R type指令,stall 1个周期(1EX->2ID)
add $a3,$a2,$a1IF ID EX MEM WB nopbeq $t0,$a3,0x10IF ID EX MEM WB - beq前1条指令为lw指令,stall 2个周期(1MEM->2ID)
lw $a3,0($a2)IF ID EX MEM WB nopnopbeq $t0,$a3,0x10IF ID EX MEM - beq前2条指令为lw指令,stall 1个周期(1MEM->3ID)
lw $a3,0($a2)IF ID EX MEM WB add $t3,$t2,$t1IF ID EX MEM WB nopbeq $t0,$a3,0x10IF ID EX MEM
延迟槽技术
即使将beq的判断前移到ID阶段,在beq之后也必须stall一个周期。可以在stall周期内执行一些必定要执行的指令,这就是延迟槽技术。
无特殊说明使用延迟槽技术的情况下,即使beq后面的指令必定执行,也必须要stall。
预测
- 静态预测:总预测分支不执行或者执行,错误则撤销指令。若预测失误会导致不必要的流水线重置。
- 动态预测:在IF阶段进行分支预测缓存,可以用PC(或者PC的低位地址)为索引,记录过去是否跳转。
实现过程:
clock 1(IF):
在第一次执行beq指令时,建立BHT和BTB,并存下1)指令地址 2)最终是否跳转 3)跳转目标地址;在之后执行beq指令时,查询指令地址是否在BHT和BTB中,若不存在,建立新的条目;若存在,根据历史记录判断是否跳转;若跳转,取出目标地址作为下一条指令的IF地址。
clock 2(ID):
根据预测目标地址取出指令。
j hazard
考虑如下指令:
|
|
j label |
IF | ID | EX | MEM | WB | ||
| stall | |||||||
add $a3,$a2,$a1 |
IF | ID | EX | MEM | WB |
j在ID阶段完成目标地址的计算,需要stall一个周期。
**但这种做法是错误的!**因为流水线直到ID阶段才能知道取出的指令为j,而此时下一条指令只能已经从指令存储中取出,只能延后执行,而不能不执行。
于是我们不进行硬件阻塞。j指令执行完ID阶段时,可以判断出执行的是j指令,此时下一条指令(实际上不会执行)也执行完IF阶段,但之后的步骤都会被flush掉,ID阶段生成的新地址也被用于载入下下一条指令。从时间上看还是stall了一个周期。
j label |
IF | ID | EX | MEM | WB | ||
add $a3,$a2,$a1(next) |
IF | x | x | x | x | ||
add $a3,$a2,$a1(jump target) |
IF | ID | EX | MEM | WB |
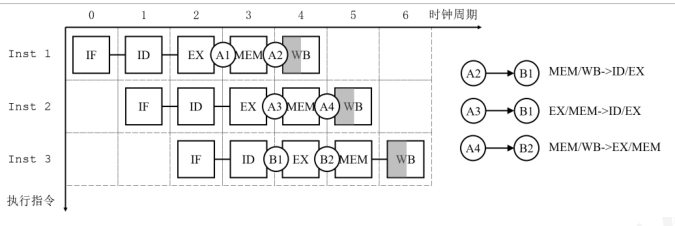
转发方式总结
- 数据冒险
- A2->B1 R型的前前条为R型
- A3->B1 R型的前条为R型
- A4->B2 lw-sw转发
此外,A4->B1无法转发,对应于lw-R型必须stall一个周期。
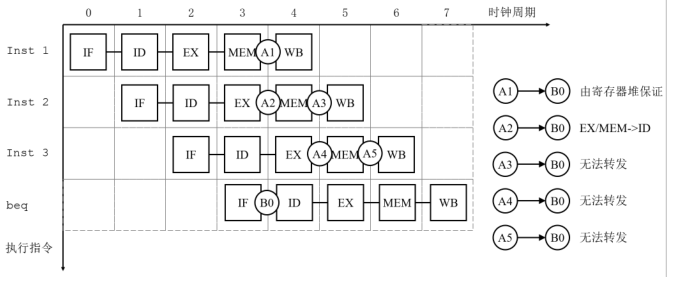
- 控制冒险(beq)
- A2->B0 beq的前前条为R型,可以使用转发解决
- A3->B0 beq的前前条为lw,需要stall 2个周期
- A4->B0 beq的前条为R型,需要stall 1个周期
- A5->B0 beq的前条为lw型,需要stall 2个周期
注意在转发时不能跨时钟周期转发,比如上上条指令ALU的结果输出不能直接转发,必须要经过MEM/WB寄存器。
考虑冒险的数据通路设计
Forward Unit
R-R type(1)
若R型的前条为R型,则可能需要从EX_MEM寄存器中转发至EX阶段:
|
|
R-R type(2)
若R型的前前条为R型,则可能需要从MEM_WB寄存器中转发至EX阶段:
|
|
最后一个判断条件是为了避免以下情况(前两条指令都是以关联寄存器为目的寄存器的时候,需要转发最新的数据,其数据来源是前一条,而不是前前条):
|
|
综上可知,EX阶段的forward单元可以描述为(以操作数1为例):
|
|
lw-sw type
若sw的前条为lw,则可能需要从MEM/WB寄存器中转发至MEM阶段:
|
|
综上可知,MEM阶段的forward单元可以描述为:
|
|
beq
若beq的前前一条指令为R type,则需要将EX_MEM中的ALU计算结果转发至ID阶段:
|
|
综上可知,ID阶段的forward单元可以描述为:
|
|
Hazard Unit
lw-R type
|
|
beq
|
|
当 beq 前一条指令为 lw 指令时,我们阻塞流水线一个周期,在 lw 和 beq 中间插入一个气泡。此时这一情况自动退化为前前一条指令为 lw 的情况,会被上述逻辑再次处理,因此最终还是会完成 2 个周期的阻塞。
Flush Unit
使用flush[i]清除第i级流水线上执行的指令(对应4级流水寄存器以及最终写回的寄存器堆):
|
|
流水线CPU异常处理
假设有3种异常:badop,IRQ(外部中断),ALUExp。
Exception被放置在EX阶段,因此badop要经过一次ID/EX寄存器。
触发异常时,该单元会flush掉当前指令的EX/MEM寄存器,下条指令的ID/EX寄存器,下下条指令的IF/ID寄存器。(注意flush由hazard和exception单元共同控制)
扩展技术
指令级并行
超级流水线
用于缩短时钟周期。
多发射
用于降低CPI。
-
超长指令字 静态决定让哪些指令同时执行(在编译阶段由编译器决定)。
-
超标量 动态决定哪些指令同时执行 (在运行时由硬件决定)。

IOI-IOC,IOI-OOC,OOI-OOC
线程级并行
超线程
多核处理器
$a$为并行部分的比例,$n$为并行部分的加速比。 $$ S=\frac{1}{(1-a)+\frac{a}{n}} $$
异构计算
单指令流多数据流,具有更大的并行度,设计相对比较简单。