method
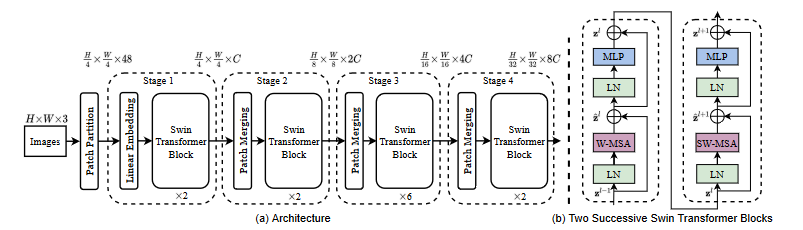
整体上看,Swin的结构类似于PVT,呈现出一种金字塔架构。
为什么金字塔结构如此重要?FPN理论认为,不同尺寸的特征图拥有不同的感受野,同时还有池化操作,从而能够很好地处理这个物体不同尺寸的这个问题(这点可以参考论文U-Net)。这样的模型更适合使用密集型任务。
code
Patch Merging
|
|
|
|
这部分首先将特征图不同位置的信息提取出来,组成4张新的特征图,然后在通道维度上进行拼接,通道数就扩大为了原来的4倍,最后通过投影将通道数缩小为之前的一半。如下图:
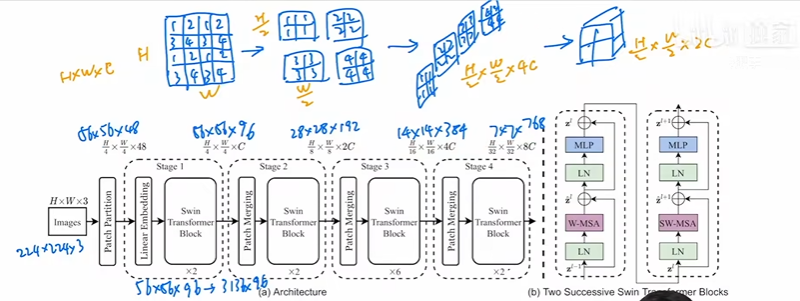
提取方法如下:
Swin Transformer Block
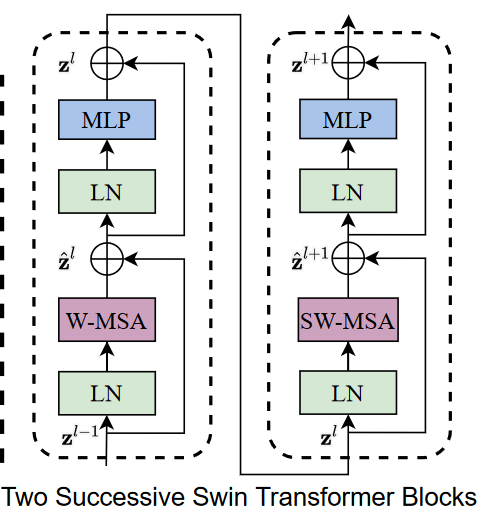
首先需要说明的是,两个transformer层合在一起才算是swin transformer的一个基本单元。两次attention作用的位置不同:
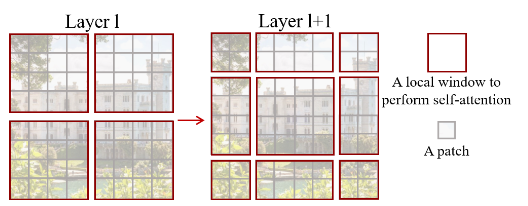
Window Based Attention
|
|
首先注意到输入的中间维度是49。这是因为swin的window size为7,这意味着一个window中一共包含49个patch。
|
|
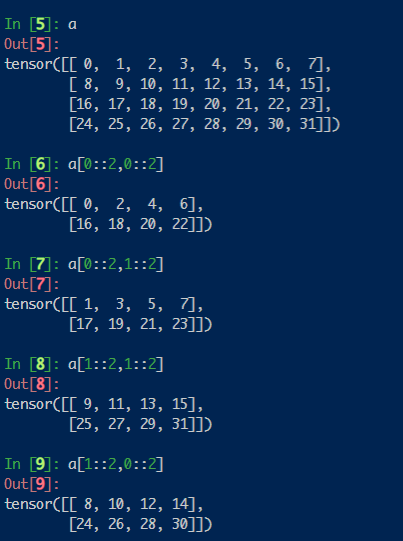
代码通过window_partation操作,将一个batch内的图片切分为若干个长为49的序列,然后在此序列中做attention,从而减小计算量。
Shift Window
swin transformer在奇数层的window不shift,但在偶数层shift,这点在层数的设置上也可以看出:
|
|
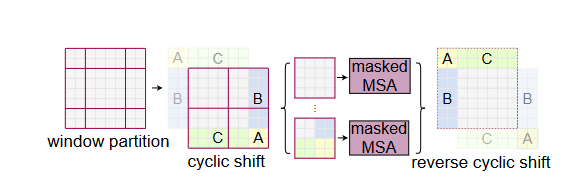
对于cyclic shift的形象解释:
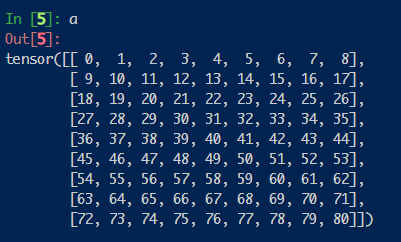
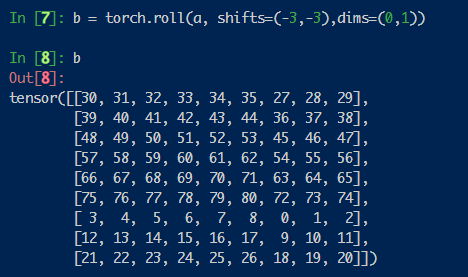
而后是mask机制。在window shift之后,为了并行计算,图片仍然被划分为4个大块。但为了让图片避免与不相关的部分作自注意力,我们引入了一下掩码:

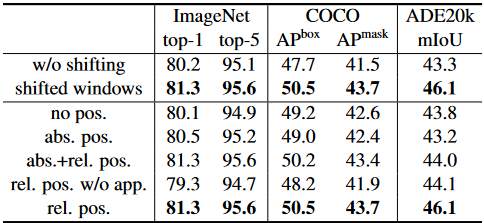
消融实验表明shift window和pos embedding在检测任务上的有效性:
Swin Transformer
|
|
类似resnet,swin会将最后一层特征图池化,而不是引入cls token。