基本概念
FLOPs:注意s小写,是FLoating point OPerations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量模型的复杂度。
FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
AlexNet
AlexNet虽然不是轻量级卷积,但是其引入了分组卷积的概念:
分组卷积的输出特征图的每个通道,只和输入特征图的一部分通道有关,而这部分通道,就是一个分组 (Group)。如下图所示,假设输入特征图的尺寸为 Cin×H×W,分为3组进行分组卷积,那么,对于每一组,输出特征图的通道数是 Cout3 ,卷积核大小为 Cin×K×K ,最后只需要将各个分组的计算结果按照通道进行连接(Concat)即可。
分组卷积可以将参数量减少为之前的$\frac{1}{G}$,其中$G$为分组数量。
SqueezeNet
- 在卷积层总数量不变的情况下,将网络中的大部分卷积层的卷积核大小设置为1x1。
- 引入一个1x1卷积层进行通道降维,减少3x3卷积的输入通道数以减少其参数 量(减少的参数量比额外引入的1x1卷积层参数量更多)。
- 在网络的更深层进行降采样,让浅层的激活值具有更大尺度,以提升性能。
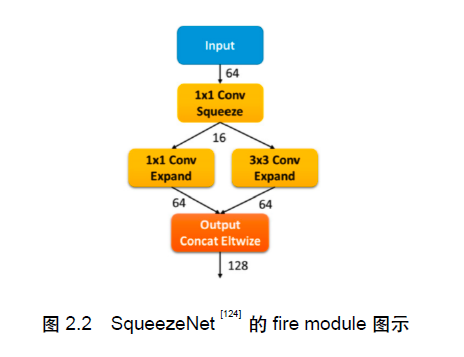
具体来说,压缩部分为一个1×1的卷积层,将输入的激活值压缩到更少的通道数目,后续的拓展部分则由两组在通道上并列的1×1与3×3卷积组成,将通道拓展回原本的数目。
MobileNetV1
核心思想:MobileNetV1就是把VGG中的标准卷积层换成深度可分离卷积就可以了。
深度可分离卷积就是将普通卷积拆分成为一个深度卷积和一个逐点卷积。
一个输入通道数为$C_{in}$、输出通道数为$C_{out}$、卷积核大小为$K$的卷积层可以分解为逐深度的(通道维 度)和逐点的(空间维度)的两个卷积。逐深度卷积层的输入输出通道均为$C_{in}$,卷积核大小为$K\times K$,个数为$C_{in}$,逐点卷积是一个输入通道数为$C_{in}$、输出通道数为$C_{out}$的$1\times1$的卷积层。
与传统卷积的对比如下:
| 计算量 | 参数量 | |
|---|---|---|
| 普通卷积 | $C_{in}\times C_{out}\times W \times H \times K^2$ | $C_{in}\times C_{out}\times K^2$ |
| 深度可分离卷积 | $C_{in}\times W \times H \times K^2 + C_{in}\times C_{out}$ | $C_{in}\times K^2 + C_{out}\times C_{in}$ |
需要指出的是,论文中使用的激活函数是ReLU6。
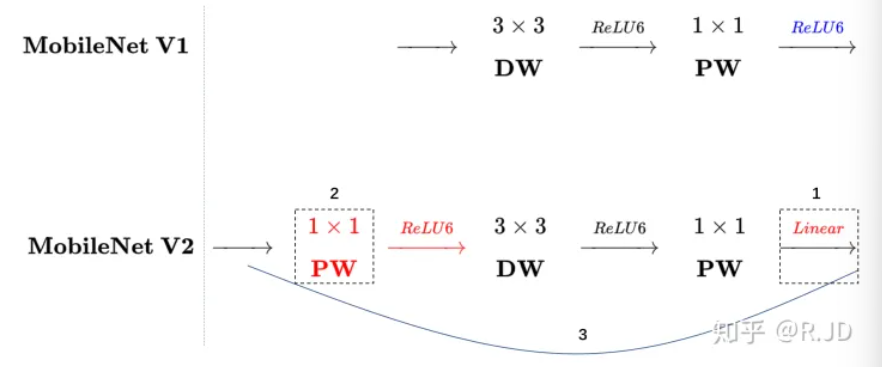
MobileNetV2
MobileNetV1中的深度可分离卷积表征能力相对受限,例如,网络的某个部分出现全0,这主要由ReLU引起。据此,MobileNetV2提出了提出了线性瓶颈层和逆残差结构。
Linear Bottleneck
对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。因此,我们将最后一层的ReLU6换成线性激活函数。
Inverted residuals
深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道。如果来的通道很少的话,DW深度卷积只能在低维度上工作,这样效果并不会很好。可以在DW深度卷积之前使用PW卷积进行升维,再在一个更高维的空间中进行卷积操作来提取特征:

对比一下V1和V2的层结构:
MobileNetV3
- 0.网络的架构基于NAS实现的MnasNet(效果比MobileNetV2好)
- 1.引入MobileNetV1的深度可分离卷积
- 2.引入MobileNetV2的具有线性瓶颈的倒残差结构
- 3.引入基于squeeze and excitation结构的轻量级注意力模型(SE)
- 4.使用了一种新的激活函数h-swish(x)
- 5.网络结构搜索中,结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt
- 6.修改了MobileNetV2网络端部最后阶段
ShuffleNet
ShuffleNet更关注计算量的优化,即如何提升通道数又同时保持模型的计算量较小。其核心设计理念是分组卷积与通道重排。
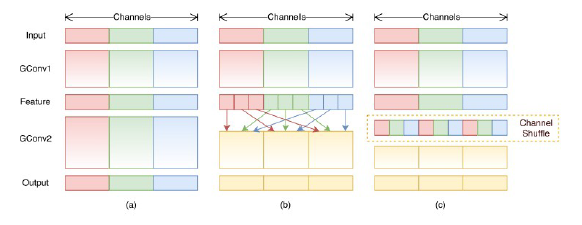
分组卷积的思想同AlexNet,ShuffleNet更进一步,将MobileNet的1x1逐点卷积层也采取分组卷积的方式:
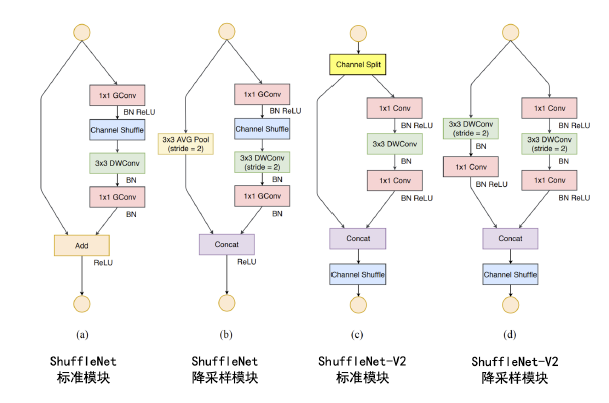
这会带来一个问题:由于分组卷积的各个组的计算独立,如果连续两个卷积层都使用 了分组卷积,会导致信息无法在组间交互。对此,ShuffleNet采用通道重排策略:
ShuffleNetV2
本文提出了轻量级模型设计的4种准则:
- 同等通道大小最小化内存访问量
- 过量使用组卷积会增加MAC
- 网络碎片化会降低并行度
- 不能忽略元素级操作
ShuffleNet几乎踩中了以上所有的坑,对此V2模型给出如下解决方案:
- 引入channel spliting,在输入通道维度切分并仅传给两个分支,其中一个分支使用直 通。另外一个分支为三个有着同样输入输出通道数的卷积,且两个1x1卷积不使用分组卷积。
- 最后将两个分支的输出通道做拼接和重排、而不是逐元素相加,而且通道的拼接-重排-切分被合并为一个操作。
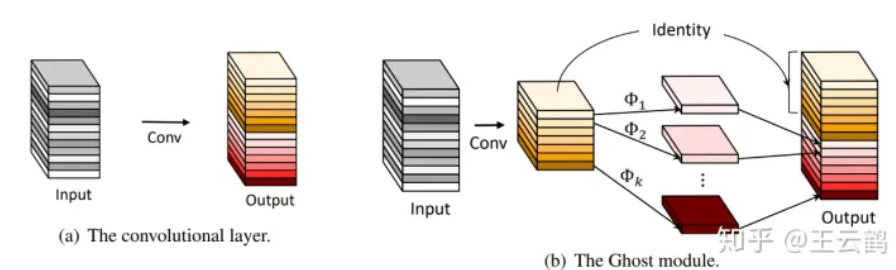
GhostNet
在一个训练好的深度神经网络中,通常会包含丰富甚至冗余的特征图,以保证对输入数据有全面的理解。作者提出了一种新颖的Ghost模块,可以使用更少的参数来生成更多特征图。具体来说,深度神经网络中的普通卷积层将分为两部分。第一部分涉及普通卷积,但是将严格控制它们的总数。给定第一部分的固有特征图,然后将一系列简单的线性运算应用于生成更多特征图。
code
|
|